无监督学习站起来了!Facebook第三代语音识别wav2vec-U,匹敌监督模型,Lecun看了都说好
【新智元导读】Facebook在语音识别上又出重磅新作,继wav2vec, wav2vec 2.0以来,又出完全不需要监督数据的wav2vec-U,小众语言也能用语音识别啦!
相比显示器、鼠标、键盘这些传统的人机交互方式以外,随着语音识别技术的逐渐成熟,和电子产品进行「对话」也逐渐成为一种稀松平常的人机交互。
无论是给计算机或其他设备下达指示,还是回答用户的问题,语音识别在各个方面让电子产品的使用变得更加容易,无需学习,想要干什么只要跟他「说」就可以了。
但是直到今天为止,语音识别这项技术还是只适用于全球数千种语言中的一小部分,因为高质量的语音识别系统需要从大量转录的语音音频中训练得到。
这些数据并不适用于所有的语言、方言和说话风格。
不同场景下的语音也存在大量的差异,例如,英语小说的转录录音,对于帮助机器学习理解一个点菜的巴斯克人或者一个做商业演讲的菲律宾人,几乎没有任何帮助。
为了解决这个难题,Facebook开发了一个全新的语音识别系统,wav2vec Unsupervised (wav2vec-U) ,这是一种完全不需要转录数据的语音识别系统的方法。
它的性能已经能够和几年前最好的监督模型匹敌,而这些模型需要将近1000小时的转录语音的训练数据。
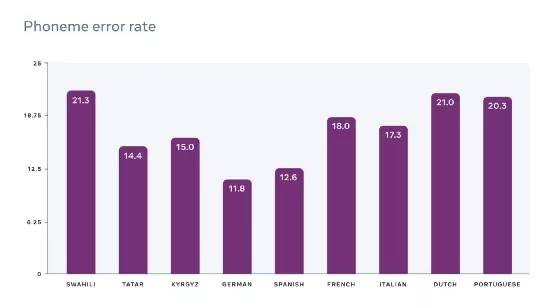
wav2vec-U已经成功在斯瓦希里语、塔塔尔语等多种小众语言上进行测试,因为缺乏大量的标记训练数据,这些语言目前还没有高质量的语音识别模型。
Wav2vec-U 是 Facebook 人工智能在语音识别、自主学习和无监督机器翻译方面多年努力的结果,也是建造机器的一个重要步骤,机器可以通过学习他们的观察来解决各种各样的任务。
作者们认为,这项工作将使语音技术可以为世界上更多人所用
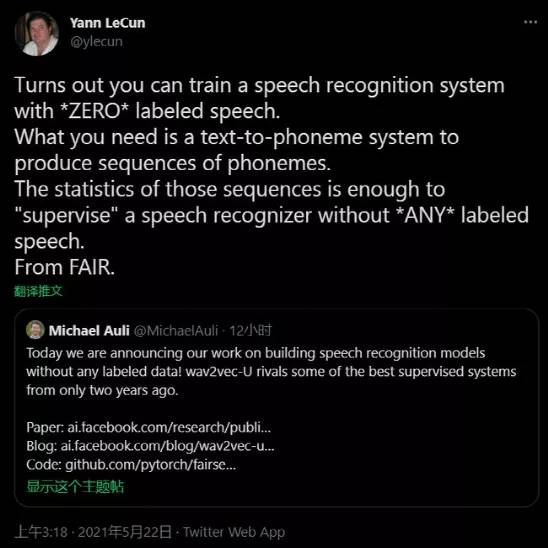
图灵奖得住Yann LeCun也发推特祝贺,表示这是足以匹敌监督学习的非监督模型。
模型原理
Wav2vec-U 模型纯粹从录制的语音音频和未配对的文本,不再需要转录
与之前的 ASR 系统相比,Wav2vec-U的框架采用了一种新颖的方法: 该方法首先从未标记的音频中学习语音的结构。
使用自监督模型 wav2vec 2.0和一个简单的 K平均算法方法,能够将录音分割成与单个声音松散对应的语音单元。(例如,单词 cat 包括三个发音: “/k/”、“/AE/”和“/t/”。)
为了学习识别音频录音中的单词,则训练了一个由生成器和鉴别器组成的对抗网络(GAN)。生成器采用embedding在自监督表示中的每个音频片段,并预测对应于语言中某个声音的音素。
生成器的训练方式是试图欺骗鉴别器,然后评估预测的音素序列看起来是否真实。在训练的初始阶段,识别的效果非常差,但随着时间的推移,准确率也不断提高。
判别器(discriminator)本身也是一个神经网络,通过训练它判别生成器的输出,来判断是否是真实存在的还是 伪造的音素。
这样训练的到的判别器就学会了区分生成器的语音识别输出和真实文本。
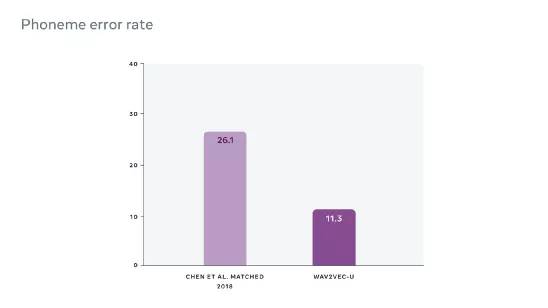
wav2vec-U 在 TIMIT 基准上对它进行了评估,与第二好的无监督方法相比,它将错误率降低了57%
除此之外,研究人员还对将 wav2vec-U 与 Librispeech 基准上的监督模型进行性能对比。在 Librispeech 基准上,监督模型通常使用960小时的转录语音数据来训练。
在没有标注数据的情况下, wav2vec-U 与几年前的最新技术一样准确。这表明语音识别系统在没有监督的情况下可以达到很好的质量。

TIMIT 和 Librispeech主要测量了模型在识别英语语音的性能,大量的、广泛可用的标记数据集能够产生足够好的语音识别技术
然而,监督模型只能对有标注数据的场景、语言才有效。
对于那些几乎不存在标记数据的语言来说,非监督语音识别才是最有效的方式。
因此,研究人员在其他语言上尝试了这个模型方法,比如斯瓦希里语、鞑靼语和吉尔吉斯语。
像语音识别这样的人工智能技术不应该只让那些世界上使用最广泛的语言之一的人受益。减少AI模型对注释数据的依赖是扩大对这些工具的访问的一个重要部分。
Facebook 的人工智能最近在这方面取得了快速的进步,先是引入了 wav2vec,然后是 wav2vec 2.0,现在是 wav2vec-U。
最重要的是,人们也并不一定是通过标签数据来学习,而是通过倾听周围的人来学习许多与语言相关的技能。这表明有一种更好的方法来训练语音识别模型,这种模型不需要大量的标记数据。开发这些更智能的系统是一个伟大、长期的科学愿景, wav2vec-U将是重要的一步。
编辑按:本文转载至微信公众号 “新智元”贝壳投研经授发布
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)
/阅读下一篇/
姚期智亲自授课!清华大学成立量子信息班,首批计划招收20人














脱水研报
-
投资要学会做三件事,一是有稳妥的知识结构,二是有稳定的情绪,三是不要让你的情绪侵蚀掉你的知识结构。我一直都在学习怎样分析公司价值,却很少考虑情绪对投资的影响,这
-
多氟多主要从事高性能无机氟化物、电子化学品及锂离子电池的研发和生产,是我国无机氟化工行业最早的上市公司之一,无水氟化铝等产销多年维持全球第一。据首创证券研报分析
-
中国长城科技集团股份有限公司(简称“中国长城”)成立于1997年,是中国电子网络安全与信息化的专业子集团,于1997年6月在深交所主板上市,公司主营业务包括高新
-
第二个问题:有没有哪些财务指标能帮我们避雷,避开那些可能会踩雷的企业?如果只选一个财务指标,你会选谁?今天这篇文章小北会从实用性的角度出发,聊下对上面净资产收益
-
1.毛利率高、净利率高,盈利能力强,具体行业利率水平有差别;2.营收和净利润多年持续增长,业绩稳健。不过股市有个真理:没有一直涨的公司,好公司也逃不过这条铁律。




名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资





热点题材
-
另有业内人士透露,电网规划专家初步建议,“十四五”期间规划的特高压工程数目在16条左右,以直流线路为主,主要负责输送新能源,助力实现“双碳”目标。电网投资一直是
-
点评:换电技术不仅为电动汽车提供了目前最快速的补能方式,在车辆电池全生命周期的健康管理、电网的削峰填谷等领域都有着不可忽视的积极作用。2020年《政府工作报告》
-
今年一季度,新能源车中的L2级智能网联汽车渗透率已经达到30.9%,智能网联化汽车在运行过程中的数据安全、信息安全等问题日益凸显。开源证券陈宝健表示,在全球范围
-
点评:国际权威机构Statista的分析,2020年全球数据产生量预计47ZB,随着新兴技术的快速发展,预计2035年全球数据量将增至2142 ZB,年复合增速
-
铟是伴生的非计价品种,全球铟矿的开采成本远高于副产铟,供给来自头部锌冶炼企业从废渣中回收。主要包括原生铟和再生铟。回顾铟金属涨价周期:2005年短缺价格高点在1





最新资讯
-
价格的变动反映着背后供求关系的变化,价格回升往往预示着行业景气度的回升,在这个时候,挖掘有潜力的行业和公司尤为重要。我国蛋氨酸现阶段正处于成长期,国产化替代加速
-
从机构调研数量看,排名靠前的迈瑞医疗、联影医疗、澳华内镜,都属于医药行业。汽配行业中,三花智控的关注度是最高的,2023-2024年接待机构近一千家,堪称A股的
-
究其原因,一是大环境推动,二是其下游覆盖领域多,前景广阔。数据显示,2023年中国低空经济市场达到50亿元,预计到2026年将突破万亿。低空飞行与产业融合,是低
-
就在4月27日,“天工”机器人震撼亮相。这是北京人形机器人创新中心推出的产品,由小米机器人、优必选科技等参投。从实际表现看,“天工”机器人并不逊于马斯克的擎天柱
-
其所选投资标的,往往是未来确定性比较高的。数据显示,截至2023年12月31日,在70多家上市中药企中,社保基金一共投资了12家公司。其中,市值现在百亿以上的有