样本是如何产生偏差从而降低我们估计模型参数能力的?
我们来看看样本是如何产生偏差从而降低我们正确估计模型参数的能力的。在金融建模中一种广为人知的偏差类型是存活者偏差(survivorshipbias),它是按照最后时点有效准则从样本总体中选择出的样本所表现出的偏差。若我们的数据中存在存活者偏差,则在那个时间之前不存在的公司的收益过程会被忽略。例如,业绩不佳的共同基金经常倒闭(因此也就退出样本了),而业绩较好的共同基金会继续存活下去(因此仍保留在样本中)。在这种情况下,对所有样本过去收益的估计就会导致过度估计的现象,这是由存活者偏差造成的。
另一个重要的偏差是指数样本选择偏差,这种偏差是在诸如罗素1000指数(大盘股)这样的指数样本中所固有的偏差。罗素1 000指数包括了罗素3 000指数中最大型的前1 000个证券(大盘股);罗素3 000指数代表了占美国股票市场上大约98%市值的股票。为了理解选择偏差,我们利用一个类似于罗素1 000的选择法则去人为地产生随机游走。考虑人为产生的随机游走能使我们在一个可控的环境中去研究选择偏差,而不受其他现象的影响。我们形成了10 000个独立的在1 000个时期上的随机游走价格过程,每一个过程都代表一个公司的股价。构造价格过程采用如下公式
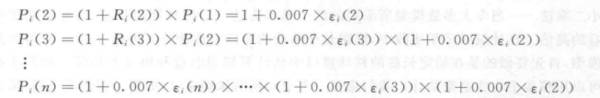
这里我们假定Pi(1)=1,波动率水平为0.007,它与现实市场价值的情况相符。我们首先来简单假定:每个公司都有相同数量的流通(outstanding) 股票。每50个时期, 我们重新选择一次,选择具有最大市值的1000个过程。在我们给定的假设条件下,它们就是具有最高市场价格的股票。这种选择方式与罗素1000的选择方式大致相同,并假定一期就代表一周。我们把这个随机游走样本称为AR1000。
随机游走的样本路径如图4.1所示。
我们将考察两个不同的总体。第一个总体中我们仅考虑在最近一个选择日所选择的那些过程。例如,在500~520的任意时间点,这个总体包括了在500期上选取的1000个过程。第二个总体包括了在整个时期内的任意时点上所选择的所有过程。第二个总体存在信息的预测问题,因为除包含最近时间外它还包含所有时间所选择的价格过程,这些过程包含的信息只能在以后才能获知。
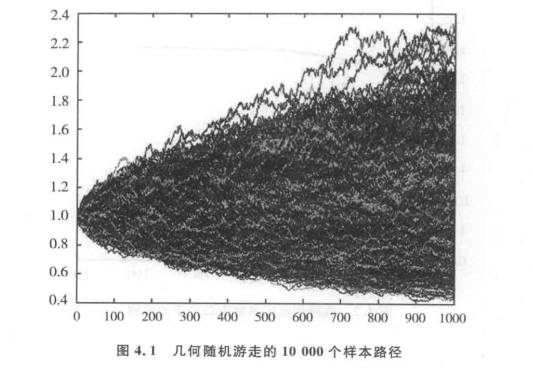
现在我们来研究平均偏差。换句话说,在时间t时,第二个总体包含了某些股票,其包含于总体的信息只能在某个时间s>t时才能获知。
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)
/阅读下一篇/
数据集在估计其平均值时是如何产生偏差的?






















脱水研报
-
这表明青岛啤酒制造和销售啤酒带来的净利润,并没有“利润表中的净利润”表示得那么多,我们看到的净利润,实际上是掺了水分后的净利润。2015年青岛啤酒非经常性损益占
-
舍得酒业是“中国名酒”企业和川酒“六朵金花”之一。80年代,沱牌曲酒因其历史悠久,文化底蕴深厚,以及独特风格,获得多项荣誉。1995年与茅台、五粮液同时被国务院
-
有朋友说不了解医药研发生产外包CRO/CDMO行业,恰好我曾经研究过,今天便来讲一下。在十九世纪的中叶有这么一个故事,美国加州传来发现金矿,许多人认为这是一个千
-
据德邦证券研报分析,亿田持续深耕产品,较早采用侧吸技术,引领行业从环吸下排步入侧吸下排,并持续优化集成灶内部结构,成功研发出风机下置集成灶,实现机身扩容推出蒸烤
-
公司成立于2003年,2012年变更为股份有限公司,2019年于科创板上市。公司是我国高端钛合金棒丝材、锻坯主要研发生产基地之一;是目前国内唯一的低温超导线材生





名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资
热点题材
-
点评:今年以来,受益于下游光伏胶膜的需求爆量,EVA树脂成为光伏产业链中的香饽饽,产品供不应求。
-
财通证券认为,当前光伏行业景气持续上行。海外市场方面,疫情对上半年海外光伏装机构成短期扰动,但出口数据已开始逐步好转,下半年需求有望持续向好。国内方面,光伏竞价
-
据中信证券测算,2025年我国有机硅在电子电器领域的市场将达到150亿元,年复合增长率为11.6%。供给方面,有机硅行业具有高准入门槛、高技术壁垒、高资金壁垒等
-
点评:《方案》提出,到2035年,合作区经济实力和科技竞争力大幅提升,公共服务和社会保障体系高效运转,琴澳一体化发展体制机制更加完善,促进澳门经济适度多元发展的
-
中药材是中华民族的宝贵资源,是中医药事业的源头,药材种子种苗是决定中药材质量的内在因素,是中药材规范化生产的保证,其质量优劣和安全直接影响中药系列产品的质量和疗





最新资讯
-
究其原因,一是大环境推动,二是其下游覆盖领域多,前景广阔。数据显示,2023年中国低空经济市场达到50亿元,预计到2026年将突破万亿。低空飞行与产业融合,是低
-
就在4月27日,“天工”机器人震撼亮相。这是北京人形机器人创新中心推出的产品,由小米机器人、优必选科技等参投。从实际表现看,“天工”机器人并不逊于马斯克的擎天柱
-
其所选投资标的,往往是未来确定性比较高的。数据显示,截至2023年12月31日,在70多家上市中药企中,社保基金一共投资了12家公司。其中,市值现在百亿以上的有
-
跨国药企为全球创新药企蹚出一条路,原来药王不仅出现在肿瘤和自免领域,内分泌(代谢)也是孕育重磅药的摇篮。诺和诺德的司美格鲁肽仅用6年时间就突破了200亿美元的年
-
当一个国家65岁及以上老年人口,占总人口比例超过7%时,就意味着进入了老龄化。2023年,我国65岁及以上人口数量2.17亿人,在总人口中占比15.4%。随着生