AI声呐眼镜来了,读懂唇语、隔空操控手机,准确率达95%
编辑按:本文转载至微信公众号“智东西”,飞鲸投研经授发布 。

智东西4月17日消息,近日,康奈尔大学未来交互智能计算机接口(SciFi)实验室发布了一款声呐眼镜EchoSpeech,该产品能根据嘴唇、面部肌肉的运动走向来识别无声命令。这款看似普通的眼镜使用了声学感应和AI技术,并配备两对扬声器和麦克风,目前可以连续识别多达31条“无声语音指令”,准确率高达95%。
EchoSpeech的主要应用场景包括嘈杂环境、不方便交谈的场合以及私密对话,还能帮助语言障碍者与他人进行交流,兼具商业消费和医疗保健功能。研发团队通过AI深度学习管道,来破译面部运动的声波传输轨道,利用卷积神经网络来解码无声语言。
此外,研发团队目前正通过资助项目Ignite来实现设备技术的商业化,未来将实现一定范围内的推广使用。
这篇名为《EchoSpeech:由声学传感驱动的眼镜上的连续无声语音识别(EchoSpeech:Continuous Silent Speech Recognition on Minimally-obtrusive Eyewear Powered by Acoustic Sensing)》的论文本月将在德国汉堡举行的CHI(Conference on Human Factors in Computing Systems)计算机协会会议上发表。
论文链接为:https://dl.acm.org/doi/10.1145/3534621
01.可识别佩戴者唇部运动,转换准确率高达95%
康奈尔大学信息科学学院博士生张瑞东,也是EchoSpeech声呐技术研究的主要参与者、论文的主要作者,在视频中演示了EchoSpeech眼镜的外形、工作原理和使用方法。

在外人看来,张瑞东像是在奇怪地自言自语,他明明在说话却没有发生任何声音。实际上,他正在向EchoSpeech念密码来解锁自己的手机,并让它播放音乐列表中的下一首歌曲。
这种像在电影中才能实现的场景不是心灵感应,而是康奈尔大学最新发布的一项新产品EchoSpeech。该产品能根据嘴唇、面部肌肉的运动走向来识别无声命令。
据康奈尔大学计算与信息科学学院助教、科学实验室主任张成说,研究团队正在通过这项技术,将声呐“转移到人们的身上”。EchoSpeech眼镜下方配备了一对麦克风和一个比铅笔头上的橡皮擦更小的扬声器,这两个工具组成了眼镜的AI声呐系统,能向面部发送和接收声波并感应佩戴者的唇部运动。
与此同时,当佩戴者试图无声交流时,研究人员开发出的深度学习算法会实时分析这些回波轮廓,目前的准确率约为95%。
在张成看来,之前的无声语音识别技术最大的障碍就在于预定命令,而且用户必须要佩戴一个不小的摄像头,这导致这项技术既不实用也难以实现。而且技术上还涉及到可穿戴摄像头的用户隐私保护问题,更需要加强安全管理。
EchoSpeech使用的声学传感技术降低了对可穿戴摄像机的要求。由于音频数据比图像或是视频数据要小得多,因此只需较小的带宽就能处理,还能通过蓝牙实时传输到智能手机上。
信息科学学院教授、论文合著者弗朗索瓦·金布雷迪尔(François Guimbretière)说:“由于数据是在用户的手机上本地处理的,没有上传到云端处理,因此可以确保所有隐私敏感信息都不会脱离用户的控制。”
EchoSpeech最普遍的使用场景是不方便交谈或是无法发言的场合,比如嘈杂的餐厅或是安静的图书馆。在公共场合当中,当人们想谈论一些较为私密的话题,或是涉及到高保密性的工作内容时,EchoSpeech可以帮用户保护好这些隐私,让外人无法听到双方的谈话。EchoSpeech还能与手写笔配对,并于CAD等设计软件一起使用,几乎不用鼠标和键盘就能完成工作任务。

谈及这项技术在未来发展中的用途时,该研究的主要参与者信息科学博士生张瑞东称,对于那些听障人士、语言表达障碍人士而言,这种无声语音技术可能是语音合成器的绝佳拍档,它可以让他们流畅自然地发出自己的声音。据悉,当前版本的眼镜声学感应电池续航时间可持续约10小时,配备摄像头版本的则是30分钟。
无论用作商业消费级智能穿戴设备,还是用作医疗保健功能,EchoSpeech将智能可穿戴技术的实用性发挥到了最大。
02.连续识别31项指令,匹配新用户仅需6分钟
EchoSpeech看上去就像一款普通的近视眼镜,但事实上并非如此。在一项12人参与的小型测试中,EchoSpeech可以连续识别出31个独立的无声命令,以及一串由被试者发出的的连续数字,它在测试中的错误率低于10%。

EchoSpeech在发布的论文中详细解释了这项技术的工作原理。
两对微型扬声器和麦克风放在镜框下方来监测面部不同侧面的运动,当扬声器发出约20000赫兹的声波时,声波会沿着一块镜片到嘴唇的特定路径传播到另一块镜片上。当来自扬声器的声波感知到唇部运动后进行反射和衍射时,麦克风会捕捉这些声波的独特模式,并为每个句子或是命令制作一个“回声配置文件”,这就像一个完整的小型声呐系统在镜片下方工作。
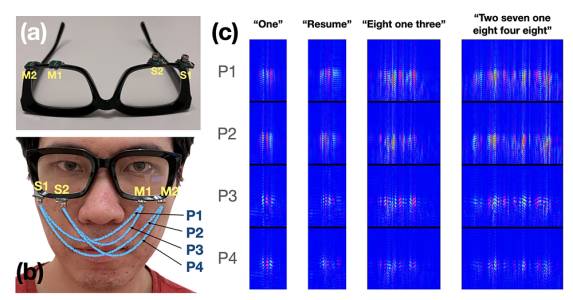
图为系统布局和回波配置文件。
在上图中,图a展示了传感器的最终位置,图b代表者信号传递路径,即从P1到P4,S1、S2为扬声器,M1、M2为麦克风。每条路径都由多个路径反射和衍射组成,它们源自源扬声器,结束于麦克风。图c是EchoSpeech对不同指令形成的声波配置文件。
通过机器学习,人们可以通过这些回声配置文件推断佩戴者的无声语言以及他们想说的单词。虽然语言模型是在选择命令上经过统一的预先训练的,但它会根据每个佩戴者来进行微调,需要约6到7分钟来为新用户进行匹配。
声波传感器通过定制的扬声器连接到微控制器上,扬声器还能通过USB电缆与电脑进行连接。
在实时演示中,团队演示了低耗能版本的EchoSpeech如何通过蓝牙和微控制器来与手机进行无线通信,设备连接到安卓手机之后,能进行面部动作预测并将转换结果传输到某个“动作键”上,发布指令来让手机播放音乐、激活语音助手或是控制手机,这就是张瑞东在演示中“自言自语”就能切换音乐播放列表的技术原理。
此外,研发团队还设计了一个定制的深度学习管道,用来破译面部运动的无声语音的声波轨道。通过回声曲线计算模型来解析面部运动模式,研究人员为EchoSpeech添加了一个基于卷积神经网络(CNN,Convolutional Neural Networks)的模型,用来解码来自回声轮廓(echo profiles)的无声语言。
研究团队还在CNN末端添加了时间递归神经网络(RNN,recurrent neural network),包括长短时记忆神经网络(LSTM)和门控递归单元层(GRU)来提高性能,在这样一个卷积循环神经网络结构(CRNN)模型上进行了实验。研究结果显示,GRU的性能明显优于LSTM,在大多数情况下,CNN与CRNN的工作方式是类似的,但在音频数量相同的时期,CNN的收敛速度比CRNN要更快一些。
03.单句、整句都可识别,静态、动态效果一样
据研究表明,隐私问题和社交尴尬是人们愿意使用无声语音助手的重要因素,他们希望不用大声说话就能交流,而且不会向外界泄露半点声音,无声语音助手在这点上很好地保护到了用户的隐私。为了满足用户对于无声语音界面(SSI)功能的更多需求,研发人员希望EchoSpeech能无限接近现实生活场景。
在实验中,团队首先设计了两组命令来检验EchoSpeech识别离散和连续语音方面的能力,并考虑到了最常见的两种情况:静态和动态。
离散研究主要关注独立命令,连续研究则关注连续无声语音识别,每位被试者都需要完整这两个测试。在数据收集过程中,电脑屏幕上出现被试者需要执行的命令,他们说出电脑上出现的词但不能发出声音,电脑摄像头将这一完整过程录制下来,清晰地检测到每位被试者的面部肌肉运动走向。

在离散研究中,每个无声指令最长的持续3秒,3秒之后就自动跳到下一个指令;在连续研究中,被试者有4秒的时间来把每句话传递给声呐眼镜,完成后按空格键或是右箭头跳到下一个指令,被试者们尽可能以自然的速度和语气“说话”。
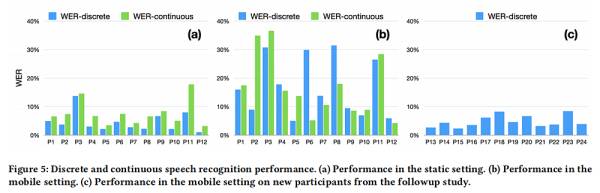
EchoSpeech在静态和移动状态下的语音识别性能对比
为了测试在静态(如坐在办公桌前)和动态(如在马路上走时)两种情形下,声呐眼镜的识别性能是否能保持稳定,一部分被试者用自己习惯的方式和速度在房间里随意走动,另外一部分则是抱着电脑走,结果显示两种情况下眼镜的表现并无显著差异。
研究团队称,用户只需提供6-8分钟的静态训练数据,就可以在静态和移动环境中无差别使用声呐眼镜,而且性能良好。
随着未来潜在的大规模部署,这种性能可以进一步改进。这将成为SSI迈向日常生活应用场景当中的坚实一步。
04.技术或将商业化,成为日常消费级产品
除了EchoSpeech以外,SciFi实验室之前还开发过一款称为EarlO的系统,该系统用配备声呐的耳机来捕捉佩戴者的面部表情,佩戴者的面部皮肤会在发声时出现移动、伸展和起皱,回声配置文件据此而进行调整,再利用算法识别这些回声配置文件,并快速重建用户面部表情,显示在数字化身上。
纽约发布罗大学的一个研究团队也研发过一款类似设备EarCommand,当我们默默说出一个单词时,肌肉运动和骨骼移动会导致耳道以独特的方式发生变形,这就意味着特定的变形模式可以与特定的单词相匹配,计算机利用这些AI算法来确定耳道的变形从而确认佩戴者所说的单词。
SciFi实验室还在积极参与康乃尔大学的Ignite项目来探索EchoSpeech技术的商业化。未来,研究人员们还将研发智能玻璃应用,用来跟踪用户的面部、眼睛和上半身的活动。张成称,未来智能玻璃将成为探知人们在日常环境中活动的重要个人智能平台。
05.结语:智能可穿戴设备进入研发成熟期。三大瓶颈有待突破
自2012年谷歌发布Project Glass智能眼镜以来,智能可穿戴设备市场可谓是备受关注。康奈尔大学研发的EchoSpeech声呐眼镜的出现证实了可穿戴设备的功能、应用场景不断得到优化拓展,可以说可穿戴设备行业已迈入研发的成熟期。
无论是EchoSpeech还是其他智能可穿戴设备也好,目前在关键技术上仍有不少瓶颈需要一一突破,包括产品形态、AI算力等。首要问题是功耗大、续航时间短导致无法用户无法长时间使用,这一弊端在配备摄像头版本的EchoSpeech上暴露得尤为明显。其次是产品功能集成度还不够完善,三是产品设计上不够日常,这就需要研发更微型的硬件来配备产品形态。
在用户实际需求和技术更新迭代的推动下,未来的EchoSpeech无论在可穿戴性、移动性、交互性以及持续性上将会有更大的改进。
来源:康奈尔大学官网
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)
/阅读下一篇/
深度分析Netflix的投资价值,虽面临激烈竞争,但前景无限光明






















脱水研报
-
2021年8月1日至9月13日,申万半导体指数涨跌幅为-17.13%,同期上证A指、沪深300指数、上证50指数和创业板指数涨跌幅分别为9.36%、3.75%、
-
不得不说,将中医药和电视剧联系在一起,是一种中医药文化的宣传,正符合我国当前对于中医药发展的支持理念。如下图,《“十四五”中医药发展规划》明确了中医药发展的目标
-
公司2021年将重点挖掘3C电子、光伏、锂电、物流、特种机床等新兴行业,打造有市场竞争力的行业解决方案队伍;同时公司将继续推进流程型组织变革,提升和改革营销体系
-
公司是国内化合物半导体龙头,在LED芯片龙头地位稳固基础上,进一步将化合物半导体业务向射频、光通信、电力电子领域发展。据中国银河证券研报分析,在LED业务基础上
-
公司知名产品有迎驾洞藏,迎驾金银星等系列,产品布局以次高端和中端为主要发力点。迎驾洞藏为近年来公司主要发力点,目标价位段100-300元,2016-2019年复





名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资





热点题材
-
业内人士表示,甲醇相对于汽油的优点是燃烧彻底、挥发性低,所排放的碳氢化合物、氧化氮和一氧化碳等有害气体少。经济性方面,甲醇汽车每百公里的成本低于传统燃油车。原料
-
至纯科技(603690)主营半导体湿法清洗设备;北方华创(002371)是国内主流的高端电子工艺装备供应商。
-
点评:干细胞治疗已经成为了现代医疗的新趋势。在新冠疫情之下,干细胞治疗表现出了更加广泛的应用前景。据权威机构数据,目前全球干细胞相关市场规模已超过千亿美元,我国
-
业内人士指出,全球经济逐步复苏,对于大宗商品的需求将会继续增加,而新船下水量相对有限,确保了运力的稀缺性,下半年BDI有进一步上涨空间。中信建投证券韩军表示,受
-
业内认为,短期除星链全球商用外,吉利集团旗下台州星空智联年产500颗卫星工厂预计在10月正式投产,并有望在今年内进行低轨卫星首次发射,题材有望迎来持续事件催化;





最新资讯
-
贵州茅台,经常被作为成长的标杆,自带后悔光环。近些年,光伏、锂电、创新药等高成长赛道行业的崛起,人们似乎又看到了下一个茅台的影子。可是,即便是隆基绿能、通威股份
-
北方华创、拓荆科技、中科飞测、京仪装备等公司营收均增长超50%,芯源微、中微公司、盛美上海等营收也有30%左右的增长。(部分半导体设备公司2023年业绩变化)其
-
此次智界S7再度上市,不仅全系采用宁德时代电池,搭载华为视觉智驾方案。更具看点的是,其智能座舱鸿蒙座舱4.0,还专门配置了盘古大模型,加速AI技术落地应用。由于
-
要么是独特且有价值的,它们一般具有较高的ROE和宽阔的护城河。前类企业总是层出不穷,算力上游中际旭创、天孚通信,还有创新药企业诺泰生物、艾力斯,以及当下的黄金企
-
在A股,也没有能长久稳健成长的龙头,只不过拼谁的行业成长周期更长而已。这其中,地摊经济、预制菜、人造肉等早已经是过眼云烟,即便是目前大热的AI人工智能、机器人、