利用应用处理器IP构建人工智能计算型存储系统
本文转载至微信公众号“半导体行业观察”,作者 杜芹,贝壳投研经授发布。
随着物联网、流媒体、社交媒体、人工智能模型的建模与仿真、医疗成像和其他数据密集型应用的飞速发展,推动数据爆发式增长,到2027年,全球云存储市场将以每年25.3%的速度增长,据YouTube官方博客的数据,每分钟有超过500小时的内容上传到YouTube。从市场调查报告的结果显示,预计明年将有850亿美元用于云存储。
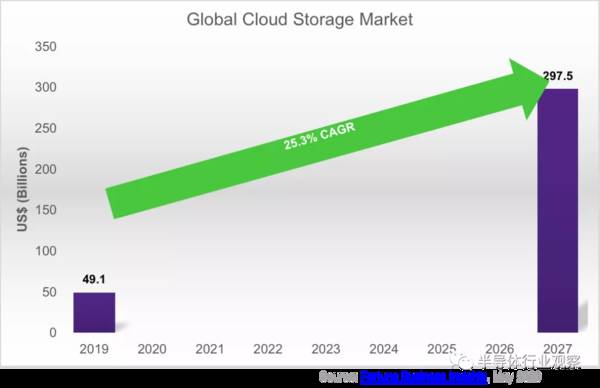
这些数据的增长需要有更大的存储容量,更高效、高性能的数据中心基础设施来存储和检索数据,更快的数据移动接口,还要能提供更多的计算资源来处理数据。数据增长也推动了数据中心运营商们加大投资,以获得更高的性能,更强的计算能力,减少数据移动(缓存相干接口,计算存储),并寻求低功率存储解决方案,同时降低碳足迹。
计算型存储被提出
数据移动占数据中心能耗的很大一部分,有效的降低数据移动的数量可以降低数据中心的耗能。举一个用数据库搜索记录的典型案例:在美国环境保护局(U.S. Environmental Protection Agency)的数据库中搜索“大气中二氧化硫含量超过健康上限75 ppb”的数据,会出现数百万条记录,但却仅有不到1/1000是相关的。传统方式是将整个数据库传输到内存中,由主机CPU处理,大大增加了不必要的数据移动。如果计算存储能够只向主机发送相关记录以供进一步分析的话,则能大大减少数据的移动量。
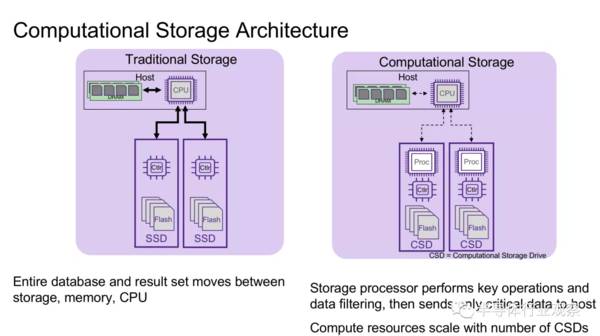
如果能为存储设备(计算存储)增加计算能力则可以提高性能和降低能耗。具体表现在:一方面可以减少数据移动和关联,比如减少延迟和网络带宽的消耗;另一方面将数据保留在驱动器内,具有更高的安全性;再者其还可以针对工作负载优化处理。

新的计算存储架构在传统的基础上,加入存储计算处理器(如下图所示),由存储处理器执行关键操作和数据过滤,只向主机发送关键数据,并且计算资源根据CSD的数量进行扩展。CSD架构的优势在于存储端的处理器可以根据应用进行优化,提供更好的性能同时减少硬件的花费。
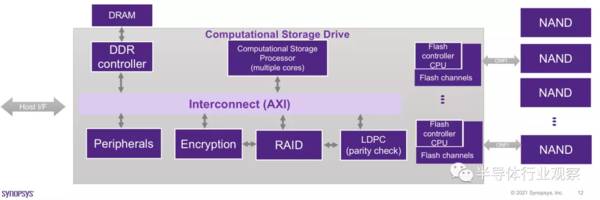
新思的计算存储处理器IP
计算存储数据流的过程通常是这样的:首先主机发起高级命令(例如查找匹配特定键的记录),然后计算存储处理器分析命令并发起读请求,接下来计算存储处理器需要构建传输描述符,描述符被分派到适当的flash通道,从flash返回的读取数据经过数据路径并由计算存储处理器进行分析(进程键匹配),将匹配记录发送到DDR(如果匹配),再将封装在主机接口协议中的DDR和DMA中的记录数据匹配到主机内存中,最后从计算存储处理器向主机发送成功的完成指示(如果没有匹配,则向主机发送错误)。
但是,存储内计算还有一些注意事项,比如SSD需要额外的处理能力,需要有友善的软件开发环境,终端应用客户能够容易的在平台上开发应用软件。为此,新思科技推出了DesignWare ARC处理器IP启用智能存储驱动器。
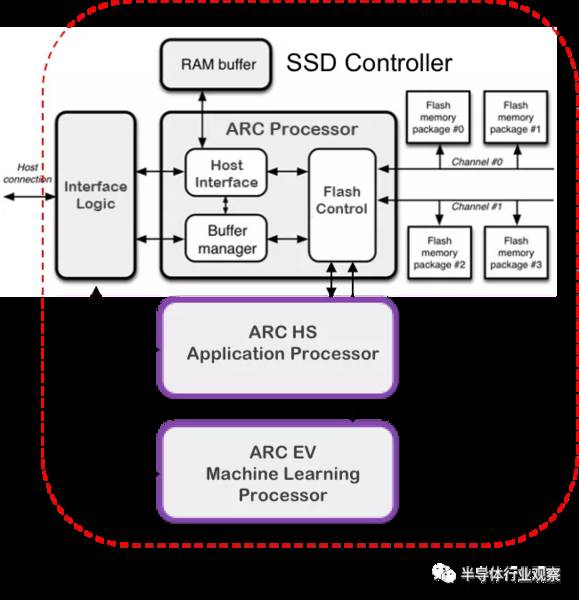
针对计算存储的应用,新思科技推出了ARC HS4x/HS4xD处理器,它是为嵌入式应用程序优化而提供的超标量内核。它是一款独立的、双发行的10级超标量体系结构,是一款高性能的嵌入书处理器,RISC提高40%,DSP性能提高2倍,每核高达5400 DMIPS@ 1.8 GHz。
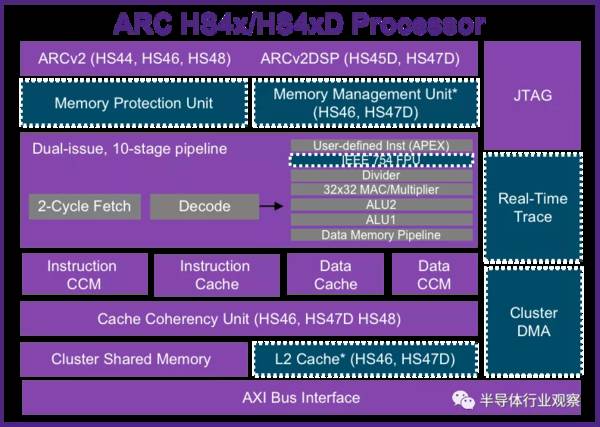
HS4xD扩展了ARCv2DSP ISA的性能范围,它拥有超过100+额外的DSP指令,并兼容流行的ARC EMxD内核,可用于额外的基带、语音/语音、音频。ARC HS4x/HS4xD处理器具有单核、双核和四核版本。还有着高效的软件开发,其优化的编译器能最大限度的提高RISC和DSP性能,以及具有优化的DSP库支持。
除了既有的DSP指令之外,ARC 处理器IP还提供了APEX (ARC Processor Extension)的技术提供用户自行添加指令来加速特定的算法。
一个案例是使用APEX获得更好的SSD效率。在这个案例中,新思的客户采用了APEX的技术新增了专用指令进行红黑树搜索算法的优化。
红黑树搜索算法是经常被使用在FTL (Flash Translation Layer)中的搜索算法,用于在内存中对I/O请求进行排序。结果发现,使用APEX指令能减少3个关键功能50%循环计数,而只增加了5%的核心面积。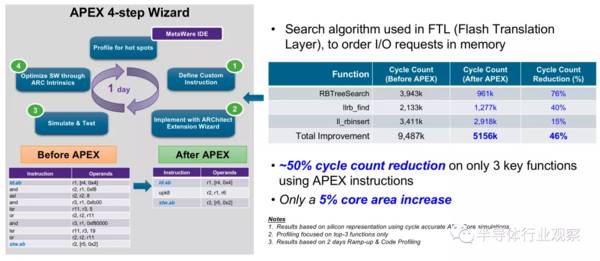
新思科技还推出了ARC HS6x处理器,它是一款基于ARCv3的面向高端嵌入式优化的64位ISA。ARCv3 ISA和微架构可扩展到12核的集群,最多16mb的共享集群缓存,向后兼容32位ARCv2内核。最高性能的ARC标量处理器可达6.1 CM/MHz(单核HS6x),其单核性能比HS4x提高20%,在HS4x (x4)上,具有最多3倍的集群性能。其优化的开发工具支持简化了软件开发,最大化了性能。ARC HS6x可在同一集群内动态调整NVMe-oF和Flash管理软件所占用的核心数量,增加软件运行的灵活性。
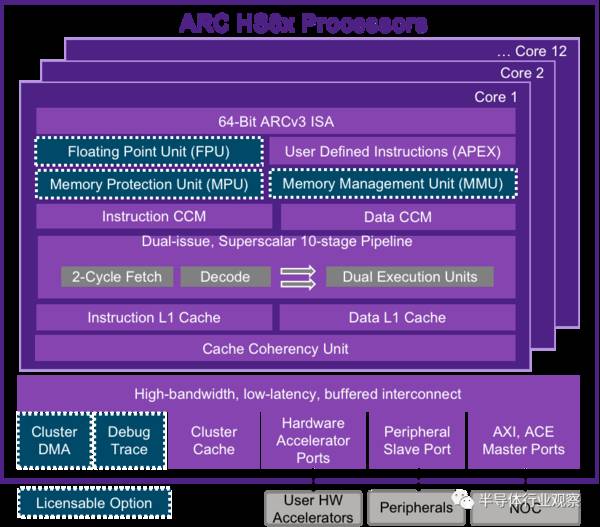
据了解,新思科技的下一代ARC可扩展集群架构,高度可扩展到高达100gb/s相干,800gb /s非相干带宽;能最多拓展至12个ARC核,外加16个客户IP和IO设备接口;所有的核心和集群内存都可以在它们自己的时钟和电源域中运行。

AI是未来存储解决方案的一部分
人工智能正在迅速发展,且是一项不可或缺的技术。为什么人工智能会出现在存储领域?因为人工智能需要数据,而数据就要存放在存储中。而且边缘的数据正在大幅增长,移动数据的“代价昂贵”。其实大多数人工智能处理可以在存储中完成。人工智能可用于离线处理数据,然后根据需要将其移动到数据中心或云。
AI在存储中的应用有很多,如预测热点和冷数据、根据需要的访问确定数据存储位置、数据生命周期管理、从存储的数据中发现洞察力、创建元数据(关于数据的数据)、进行对象检测和分类、存储分层(平衡速度,存储成本)、提升SSD性能和QoS、延长SSD寿命/提高可靠性、低写放大因子(WAF)、数据聚类、flash纠正错误、故障预测。
具有可编程神经网络加速器的人工智能处理器经常使用在计算存储处理架构中实现,下图是新思科技的ARC EV 处理器,拥有向量DSP以及神经网络加速器的异质架构,非常适合用在人工智能存储的应用中。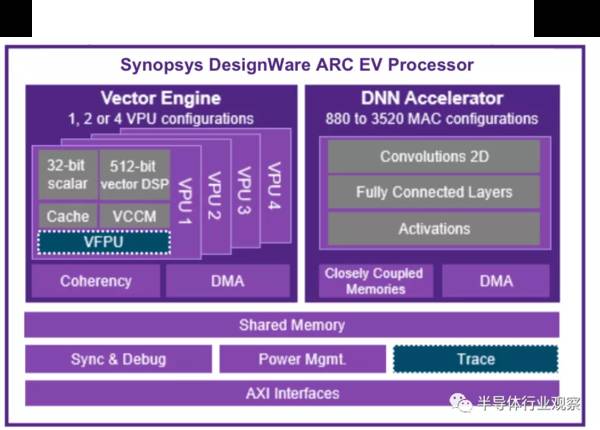
总结
传统的数据从驱动器移动到计算,需要跨接口和协议移动,消耗大量时间和增加延迟,而且移动数据要消耗能量,数据复制多次,具有较低的安全。在这样的情况下,存储内计算被提出。存储内计算能将计算在存储装置中完成,最大限度地减少数据移动,减少延迟,最大限度地减少能量的消耗。数据将保留在驱动器中,本地数据具有更高的安全性。可以针对工作负载优化处理。人工智能(NN架构)也将逐渐成为未来存储解决方案的一部分。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
飞鲸投研从多维度分析,整理了一份《成长50》的名单,可以关注同名公众号:"飞鲸投研":feijingtouyan,进行领取(点击复制)
/阅读下一篇/
中国射频芯片产业背后的“贵人”


















脱水研报
-
十多年前,维维豆奶还是很风光的,它曾是国内最畅销的饮品之一,连续多年拿下市场占有率NO.1、销量NO.1,是当之无愧的“豆奶一哥”。“维维豆奶欢乐开怀”的经
-
此次降准为全面降准,共计释放长期资金约5300亿元。虽然没有明显超预期,但“稳增长”以及稳定宏观经济大盘的预期再次传递给市场。在此背景下,率先受益于降准的房地产
-
目前公司主要包含三大产品和服务,分别是智能投影产品、投影相关配件产品和互联网增值服务。据西部证券研报分析,公司整机业务占比最高,同时以线上销售渠道为主,为公司销
-
首旅2016年完成如家私有化,跻身国内连锁酒店集团TOP3。公司旗下近20个品牌、40个产品覆盖全系列酒店业务。据浙商证券研报分析,公司将依靠较高直营店占比享有
-
公司从复读机、MP3/MP4领域做起,拥有二十余年丰富的SoC设计经验。近年来公司把握AIoT领域飞速发展的市场机遇,积极布局AIoT各细分市场,产品涵盖智慧商




名家观点
-
一隐秀路大佬就是这波主多南天的主力,今天下午又再度拉回,从同花顺超级盘口看它从水下一路点火,要不是大盘太弱了大概率能走出地天,上次也是在一片绝望中隐秀路大佬引导
-
这一周的弱势,始于外资的大幅出逃,不过,周五的弱势,却怪不了人家,参考下北上资金,尽管深港通有一定流出,但也谈不上很大,沪港通更是流入的,所以,周五的弱,纯属于
-
以岭药业:这个票近期是一路小快步上行,到了今天终于是走了加速,明天溢价问题不大,但周四涨停也说明短线资金进来了,短期估计短线资金还会关注这里,明天预计冲高问题不
-
10月份已到了最后几天,三季报也进入到了最后的集中披露,而这个时候,就要注意下不及预期的雷股了。怎么规避不及预期的可能雷股?如果对个股基本面不是很了解,还真没什
-
第二段,就是11点之后,不管是中午前的强反击,还是午后的回落,以及随后的僵持,跟北上资金的节奏几乎完全同步了,这意味着,多空双方都选择了观望,然后,才有了北上资
热点题材
-
我国建筑屋顶资源丰富、分布广泛,开发建设屋顶分布式光伏潜力巨大,有利于引导居民绿色能源消费,助力碳减排。光伏建筑一体化(BIPV)是打造绿色建筑最有效的解决方案
-
点评:据报道,截至2020年年底,全国外卖总体订单量将达到171.2亿单,同比增长7.5%。我国外卖用户规模已接近5亿人。在2月份,抖音在北京、上海、杭州等一线
-
点评:业内分析人士认为,8月开始,国内房地产与基建项目的投资将会稳中有升。与此同时,由于电厂限电,大部分水泥厂,尤其是广西、河南地区出现错峰停窑,同时还有一部分
-
上述新政解决了新能源配送工程建设的痛点,有利于推动新能源更快发展,并促进电网侧大规模独立共享储能电站的建设。国泰君安庞钧文表示,储能电站的使用将有效解决可再生能
-
今年1-2月,西南地区尿素企业由于限气停产,导致开工率大幅下滑,叠加河北疫情反扑,贸易商担心交通运输趋严,提前备货,叠加国际尿素价格大涨的多重利好叠加,尿素价格





最新资讯
-
2024年在人工智能、大模型、智能汽车等新兴应用驱动下,全球半导体行业呈现复苏态势。在这个时候,挖掘有潜力的行业和公司尤为重要,光刻领域无疑是最有潜力的领域,而
-
在小米、华为等汽车快速崛起下,特斯拉终于遭受到了压力。最新公布的财报看,特斯拉第一季度营收为213亿美元,同比下滑9%,其中汽车业务营收更是下滑了13%;公司实
-
业绩表现好的公司,市场也不吝啬给予关注,贵州茅台、宁德时代、阳光电源、山东黄金、传音控股等公司热度本来就高,有了业绩加持更加不得了。长虹美菱、微芯生物、万安科技
-
这次是华为PURA70系列,是2023年下半年Mate60系列强势回归后又一力作,不过更让人期待二季度要发布的华为折叠屏手机。4月23日,华为正式公布了折叠屏手
-
这几个月来,低空经济的热度可谓是居高不下。先是2023年12月,低空经济被确立为战略性新兴产业,有望成为新的经济增长点。后是2024年4月,亿航智能成为全球首个